Partitioning ops
This page is specific to ops. To learn about partitioning assets, see Partitioning assets.
When defining a job that uses ops you can partition it by supplying PartitionedConfig object as its config.
In this guide, we'll demonstrate to use partitions with ops and jobs.
Prerequisites
Before continuing, you should be familiar with:
Relevant APIs
| Name | Description |
|---|---|
PartitionedConfig | Determines a set of partitions and how to generate run config for a partition. |
@dg.daily_partitioned_config | Decorator for constructing partitioned config where each partition is a date. |
@dg.hourly_partitioned_config | Decorator for constructing partitioned config where each partition is an hour of a date. |
@dg.weekly_partitioned_config | Decorator for constructing partitioned config where each partition is a week. |
@dg.monthly_partitioned_config | Decorator for constructing partitioned config where each partition is a month. |
@dg.static_partitioned_config | Decorator for constructing partitioned config for a static set of partition keys. |
@dg.dynamic_partitioned_config | Decorator for constructing partitioned config for a set of partition keys that can grow over time. |
build_schedule_from_partitioned_job | A function that constructs a schedule whose interval matches the partitioning of a partitioned job. |
Defining jobs with time partitions
The most common kind of partitioned job is a time-partitioned job - each partition is a time window, and each run for a partition processes data within that time window.
Non-partitioned job with date config
Before we dive in, let's look at a non-partitioned job that computes some data for a given date:
from dagster import Config, OpExecutionContext, job, op
class ProcessDateConfig(Config):
date: str
@op
def process_data_for_date(context: OpExecutionContext, config: ProcessDateConfig):
date = config.date
context.log.info(f"processing data for {date}")
@job
def do_stuff():
process_data_for_date()
It takes, as config, a string date. This piece of config defines which date to compute data for. For example, if you wanted to compute for May 5th, 2020, you would execute the graph with the following config:
graph:
process_data_for_date:
config:
date: "2020-05-05"
Date-partitioned job
With the job above, it's possible to supply any value for the date param. This means if you wanted to launch a backfill, Dagster wouldn't know what values to run it on. You can instead build a partitioned job that operates on a defined set of dates.
First, define the PartitionedConfig. In this case, because each partition is a date, you can use the @dg.daily_partitioned_config decorator. This decorator defines the full set of partitions - every date between the start date and the current date, as well as how to determine the run config for a given partition.
from dagster import daily_partitioned_config
from datetime import datetime
@daily_partitioned_config(start_date=datetime(2020, 1, 1))
def partitioned_config(start: datetime, _end: datetime):
return {
"ops": {
"process_data_for_date": {"config": {"date": start.strftime("%Y-%m-%d")}}
}
}
Then you can build a job that uses the PartitionedConfig by supplying it to the config argument when you construct the job:
@job(config=partitioned_config)
def partitioned_op_job():
process_data_for_date()
Defining jobs with static partitions
Not all jobs are partitioned by time. For example, the following example shows a partitioned job where the partitions are continents:
from dagster import Config, OpExecutionContext, job, op, static_partitioned_config
CONTINENTS = [
"Africa",
"Antarctica",
"Asia",
"Europe",
"North America",
"Oceania",
"South America",
]
@static_partitioned_config(partition_keys=CONTINENTS)
def continent_config(partition_key: str):
return {"ops": {"continent_op": {"config": {"continent_name": partition_key}}}}
class ContinentOpConfig(Config):
continent_name: str
@op
def continent_op(context: OpExecutionContext, config: ContinentOpConfig):
context.log.info(config.continent_name)
@job(config=continent_config)
def continent_job():
continent_op()
Creating schedules from partitioned jobs
Running a partitioned job on a schedule is a common use case. For example, if your job has a partition for each date, you likely want to run that job every day, on the partition for that day.
Refer to the Schedule documentation for more info about constructing both schedules for asset and op-based jobs.
Partitions in the Dagster UI
In the UI, you can view runs by partition in the Partitions tab of a Job page:
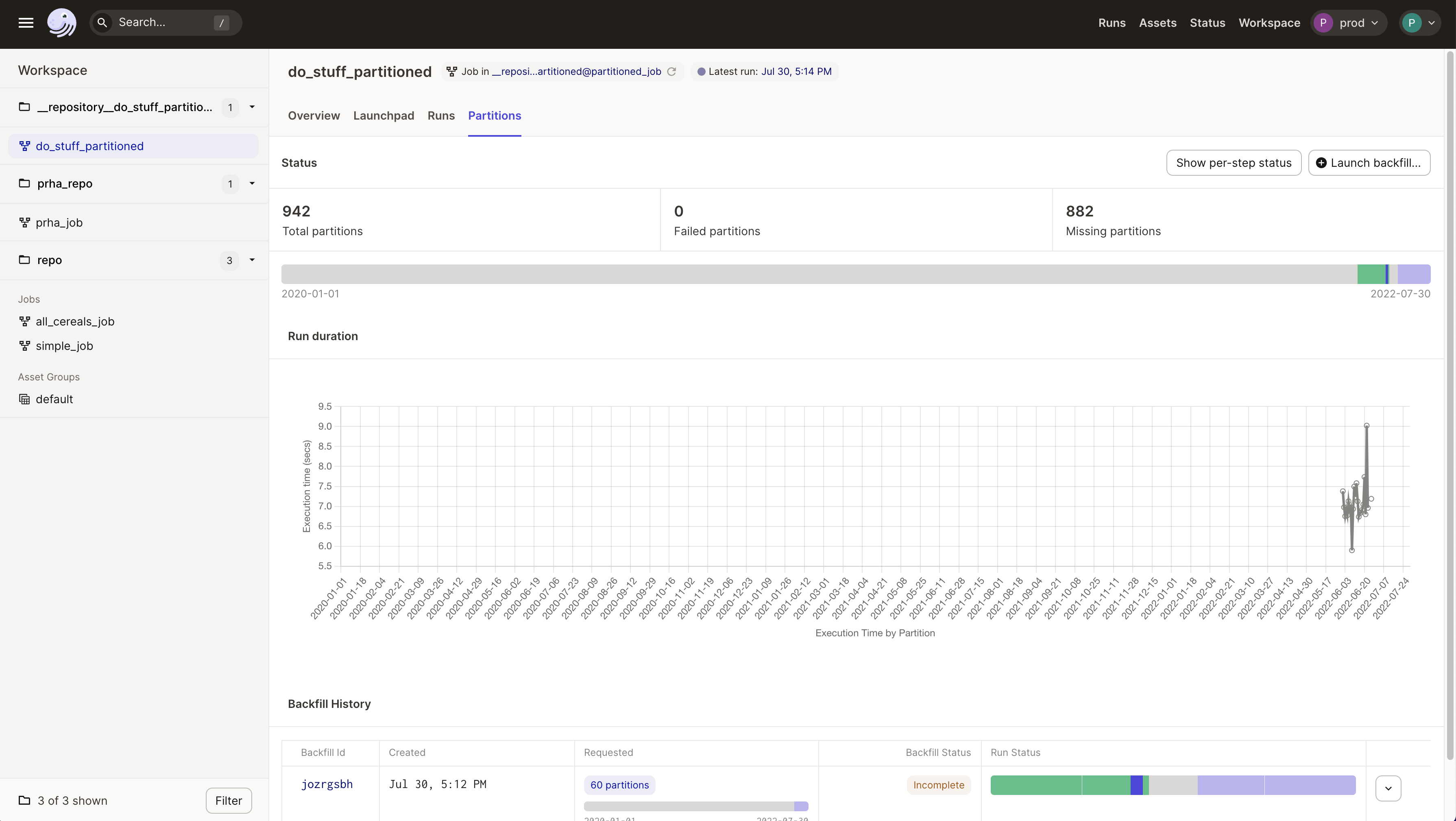
In the Run Matrix, each column corresponds to one of the partitions in the job. The time listed corresponds to the start time of the partition. Each row corresponds to one of the steps in the job. You can click on an individual box to navigate to logs and run information for the step.
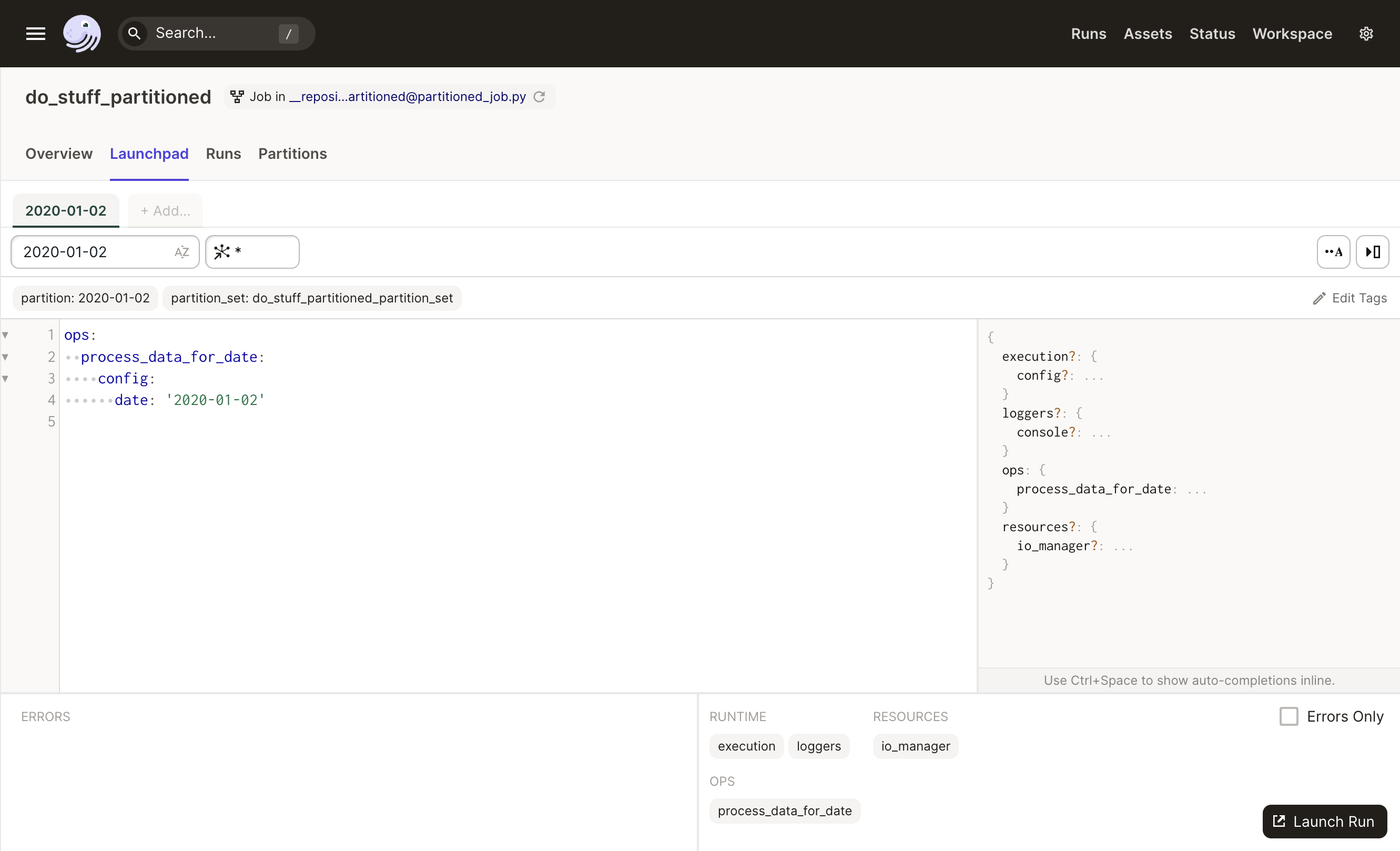
You can view and use partitions in the UI Launchpad tab for a job. In the top bar, you can select from the list of all available partitions. Within the config editor, the config for the selected partition will be populated.
In the screenshot below, we select the 2020-01-02 partition, and we can see that the run config for the partition has been populated in the editor.
In addition to the @dg.daily_partitioned_config decorator, Dagster also provides @dg.monthly_partitioned_config, @dg.weekly_partitioned_config, @dg.hourly_partitioned_config. See the API docs for each of these decorators for more information on how partitions are built based on different start_date, minute_offset, hour_offset, and day_offset inputs.