Op graphs
If you are just getting started with Dagster, we strongly recommend you use assets rather than ops to build your data pipelines. The ops documentation is for Dagster users who need to manage existing ops, or who have complex use cases.
A graph is a set of interconnected ops or sub-graphs. While individual ops typically perform simple tasks, ops can be assembled into a graph to accomplish complex tasks.
Graphs can be used in three different ways:
- To back assets - Basic assets are computed using a single op, but if computing one of your assets requires multiple discrete steps, you can compute it using a graph instead.
- Directly inside a job - Each op job contains a graph.
- Inside other graphs - You can build complex graphs out of simpler graphs.
Relevant APIs
| Name | Description |
|---|---|
@dg.graph | The decorator used to define an op graph, which can form the basis for multiple jobs. |
GraphDefinition | An op graph definition, which is a set of ops (or sub-graphs) wired together. Forms the core of a job. Typically constructed using the @dg.job decorator. |
Creating op graphs
Using the @graph decorator
To create an op graph, use the @dg.graph decorator.
In the following example, we return one output from the root op (return_one) and pass data along through single inputs and outputs:
import dagster as dg
@dg.op
def return_one(context: dg.OpExecutionContext) -> int:
return 1
@dg.op
def add_one(context: dg.OpExecutionContext, number: int) -> int:
return number + 1
@dg.graph
def linear():
add_one(add_one(add_one(return_one())))
Op graph patterns
Need some inspiration? Using the patterns below, you can build op graphs:
- Reuse an op definition
- With multiple inputs
- With conditional branching
- With a fixed fan-in
- That contain other op graphs
- That use dynamic outputs
Reuse an op definition
You can use the same op definition multiple times in the same graph. Note that this approach can also apply to op jobs.
@dg.graph
def multiple_usage():
add_one(add_one(return_one()))
To differentiate between the two invocations of add_one, Dagster automatically aliases the op names to be add_one and add_one_2.
You can also manually define the alias by using the .alias method on the op invocation:
@dg.graph
def alias():
add_one.alias("second_addition")(add_one(return_one()))
With multiple inputs
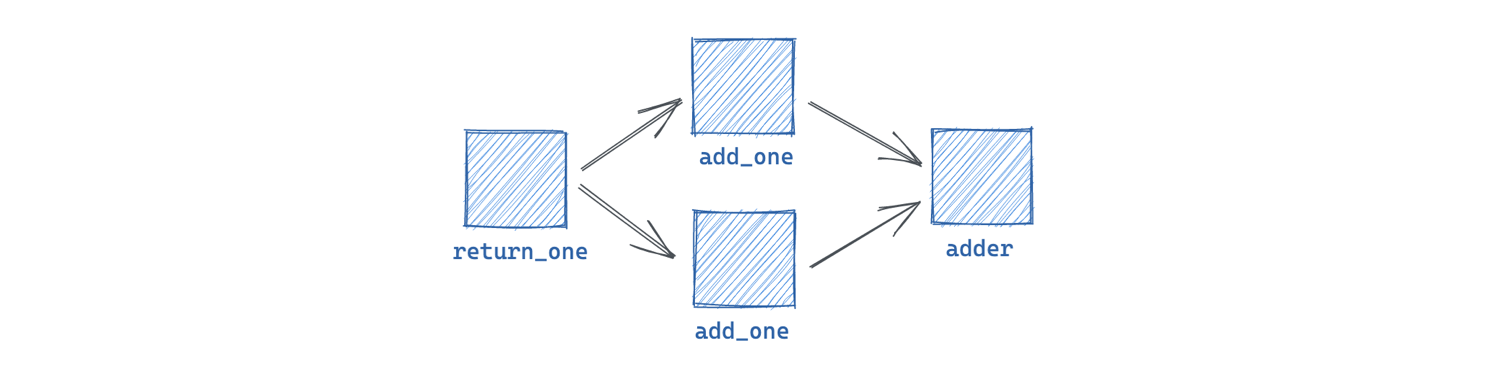
A single output can be passed to multiple inputs on downstream ops. In this example, the output from the first op is passed to two different ops. The outputs of those ops are combined and passed to the final op:
import dagster as dg
@dg.op
def return_one(context: dg.OpExecutionContext) -> int:
return 1
@dg.op
def add_one(context: dg.OpExecutionContext, number: int):
return number + 1
@dg.op
def adder(context: dg.OpExecutionContext, a: int, b: int) -> int:
return a + b
@dg.graph
def inputs_and_outputs():
value = return_one()
a = add_one(value)
b = add_one(value)
adder(a, b)
With conditional branching
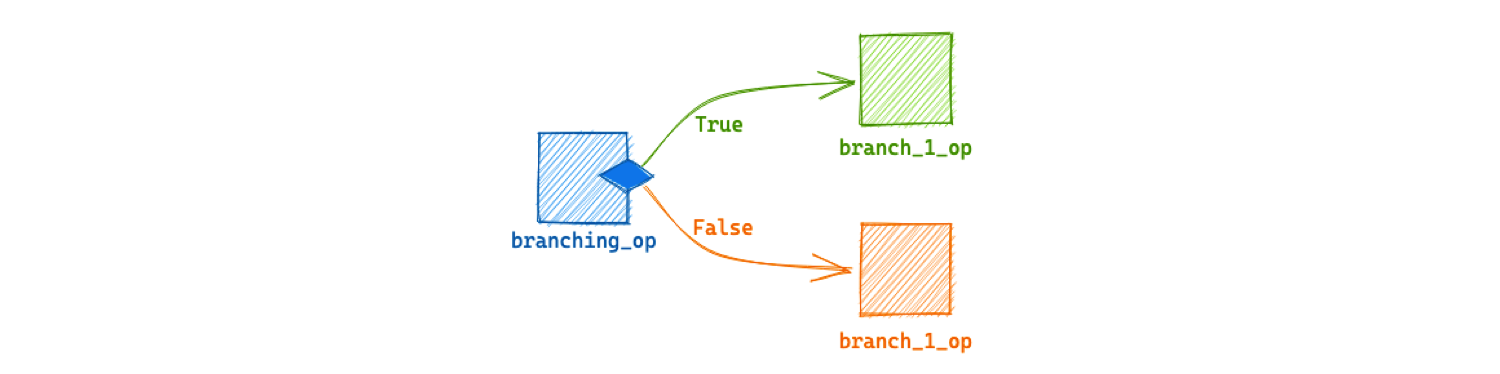
As an op only starts to execute once all its inputs have been resolved, you can use this behavior to model conditional execution.
In this example, the branching_op outputs either the branch_1 result or branch_2 result. Since op execution is skipped for ops that have unresolved inputs, only one of the downstream ops will execute:
import random
import dagster as dg
@dg.op(
out={"branch_1": dg.Out(is_required=False), "branch_2": dg.Out(is_required=False)}
)
def branching_op():
num = random.randint(0, 1)
if num == 0:
yield dg.Output(1, "branch_1")
else:
yield dg.Output(2, "branch_2")
@dg.op
def branch_1_op(_input):
pass
@dg.op
def branch_2_op(_input):
pass
@dg.graph
def branching():
branch_1, branch_2 = branching_op()
branch_1_op(branch_1)
branch_2_op(branch_2)
When using conditional branching, Output objects must be yielded instead of returned.
With a fixed fan-in
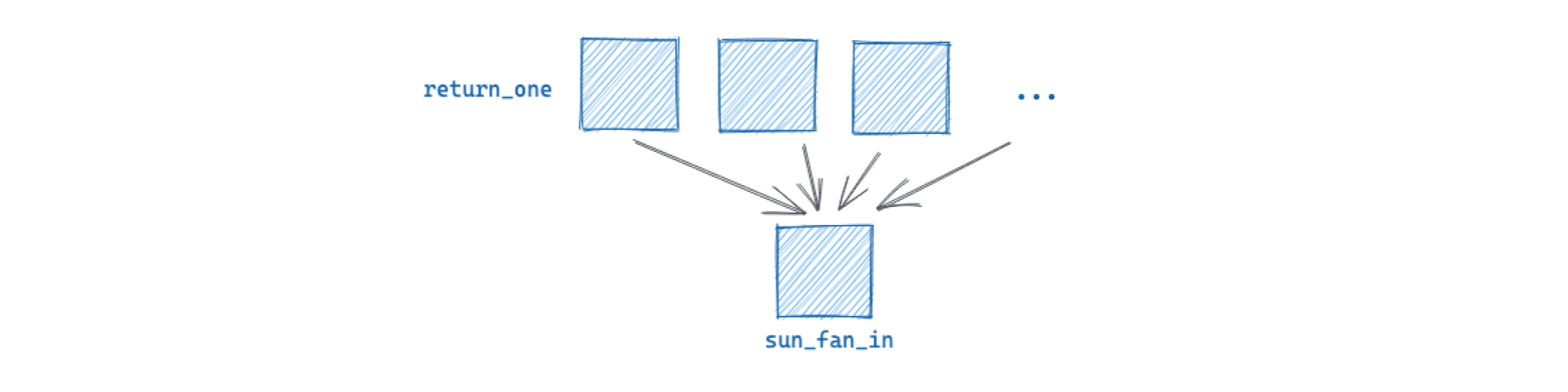
If you have a fixed set of ops that all return the same output type, you can collect the outputs into a list and pass them into a single downstream op.
The downstream op executes only if all of the outputs were successfully created by the upstream op:
import dagster as dg
@dg.op
def return_one() -> int:
return 1
@dg.op
def sum_fan_in(nums: list[int]) -> int:
return sum(nums)
@dg.graph
def fan_in():
fan_outs = [return_one.alias(f"return_one_{i}")() for i in range(0, 10)]
sum_fan_in(fan_outs)
In this example, we have 10 ops that all output the number 1. The sum_fan_in op takes all of these outputs as a list and sums them.
That contain other op graphs
Op graphs can contain other op graphs. Refer to the Nesting op graphs documentation for more info and examples.
Using dynamic outputs
Using dynamic outputs, you can duplicate portions of an op graph at runtime. Refer to the Dynamic graphs documentation for more info and examples.
Defining and constructing dependencies
Defining nothing dependencies
Dependencies in Dagster are primarily data dependencies. Using data dependencies means each input of an op depends on the output of an upstream op.
If you have an op, say Op A, that does not depend on any outputs of another op, say Op B, there theoretically shouldn't be a reason for Op A to run after Op B. In most cases, these two ops should be parallelizable. However, there are some cases where an explicit ordering is required, but it doesn't make sense to pass data through inputs and outputs to model the dependency.
If you need to model an explicit ordering dependency, you can use the Nothing Dagster type on the input definition of the downstream op. This type specifies that you are passing "nothing" via Dagster between the ops, while still using inputs and outputs to model the dependency between the two ops.
import dagster as dg
@dg.op
def create_table_1():
get_database_connection().execute(
"create table_1 as select * from some_source_table"
)
@dg.op(ins={"start": dg.In(dg.Nothing)})
def create_table_2():
get_database_connection().execute("create table_2 as select * from table_1")
@dg.graph
def nothing_dependency():
create_table_2(start=create_table_1())
In this example, create_table_2 has an input of type Nothing meaning that it doesn't expect any data to be provided by the upstream op. This lets us connect them in the graph definition so that create_table_2 executes only after create_table_1 successfully executes.
Nothing type inputs do not have a corresponding parameter in the function since there is no data to pass. When connecting the dependencies, it is recommended to use keyword args to prevent mix-ups with other positional inputs.
Note that in most cases, it is usually possible to pass some data dependency. In the example above, even though we probably don't want to pass the table data itself between the ops, we could pass table pointers. For example, create_table_1 could return a table_pointer output of type str with a value of table_1, and this table name can be used in create_table_2 to more accurately model the data dependency.
Dagster also provides more advanced abstractions to handle dependencies and IO. If you find that you are finding it difficult to model data dependencies when using external storage, check out IO managers.
Loading an asset as an input
You can supply an asset as an input to one of the ops in a graph. Dagster can then use the I/O manager on the asset to load the input value for the op.
import dagster as dg
@dg.asset
def emails_to_send(): ...
@dg.op
def send_emails(emails) -> None: ...
@dg.job
def send_emails_job():
send_emails(emails_to_send.get_asset_spec())
We must use the AssetsDefinition.get_asset_spec, because AssetSpecs are used to represent assets that other assets or jobs depend on, in settings where they won't be materialized themselves.
If the asset is partitioned, then:
- If the job is partitioned, the corresponding partition of the asset will be loaded.
- If the job is not partitioned, then all partitions of the asset will be loaded. The type that they will be loaded into depends on the I/O manager implementation.
Constructing dependencies
Using GraphDefinitions
You may run into a situation where you need to programmatically construct the dependencies for a graph. In that case, you can directly define the GraphDefinition object.
To construct a GraphDefinition, you need to pass the constructor a graph name, a list of op or graph definitions, and a dictionary defining the dependency structure. The dependency structure declares the dependencies of each op’s inputs on the outputs of other ops in the graph. The top-level keys of the dependency dictionary are the string names of ops or graphs. If you are using op aliases, be sure to use the aliased name. Values of the top-level keys are also dictionary, which maps input names to a DependencyDefinition.
one_plus_one_from_constructor = GraphDefinition(
name="one_plus_one",
node_defs=[return_one, add_one],
dependencies={"add_one": {"number": DependencyDefinition("return_one")}},
).to_job()
Using YAML (GraphDSL)
Sometimes you may want to construct the dependencies of an op graph definition from a YAML file or similar. This is useful when migrating to Dagster from other workflow systems.
For example, you can have a YAML like this:
name: some_example
description: blah blah blah
ops:
- def: add_one
alias: A
- def: add_one
alias: B
deps:
num:
op: A
- def: add_two
alias: C
deps:
num:
op: A
- def: subtract
deps:
left:
op: B
right:
op: C
You can programmatically generate a GraphDefinition from this YAML:
import os
import dagster as dg
@dg.op
def add_one(num: int) -> int:
return num + 1
@dg.op
def add_two(num: int) -> int:
return num + 2
@dg.op
def subtract(left: int, right: int) -> int:
return left + right
def construct_graph_with_yaml(yaml_file, op_defs) -> dg.GraphDefinition:
yaml_data = load_yaml_from_path(yaml_file)
assert isinstance(yaml_data, dict)
deps = {}
for op_yaml_data in yaml_data["ops"]: # ty: ignore[invalid-argument-type, not-iterable]
def_name = op_yaml_data["def"]
alias = op_yaml_data.get("alias", def_name)
op_deps_entry = {}
for input_name, input_data in op_yaml_data.get("deps", {}).items():
op_deps_entry[input_name] = dg.DependencyDefinition(
node=input_data["op"], output=input_data.get("output", "result")
)
deps[dg.NodeInvocation(name=def_name, alias=alias)] = op_deps_entry
return dg.GraphDefinition(
name=yaml_data["name"], # ty: ignore[invalid-argument-type]
description=yaml_data.get("description"), # ty: ignore[invalid-argument-type]
node_defs=op_defs,
dependencies=deps,
)
def define_dep_dsl_graph() -> dg.GraphDefinition:
path = os.path.join(os.path.dirname(__file__), "my_graph.yaml")
return construct_graph_with_yaml(path, [add_one, add_two, subtract])
Using graphs
Inside assets
Op graphs can be used to create asset definitions. Graph-backed assets are useful if you have an existing op graph that produces and consumes assets.
Wrapping your graph inside an asset definition gives you all the benefits of software-defined assets — like cross-job lineage — without requiring you to change the code inside your graph. Refer to the graph-backed assets documentation for more info and examples.
Directly inside op jobs
Ready to start using your op graphs in Dagster op jobs? Refer to the Op jobs documentation for detailed info and examples.